[규제] AI 활용 데이터 무단 수집 논란,
게임산업 영향과 전망은?
글로벌 게임산업 동향
집필: EC21R&C 김종우 선임연구원
Executive Summary
AI 기업의 스텔스 크롤링 확산과 웹 표준 위반 문제 심화
2025년 상반기 Perplexity 등 AI 기업의 robots.txt 우회 및 신원 위장 크롤링 기법 적발
Q1 2025 기준 RAG 봇 스크래핑 전 분기 대비 49% 증가, robots.txt 무시 비율 12.9%로 급증
AI 봇의 스크래핑 대 참조 트래픽 비율 극심한 불균형(Anthropic 8,692:1, Perplexity 369:1)
웹 표준의 투명성·존중 원칙 위반으로 콘텐츠 생태계 전반의 신뢰 위기 촉발
게임 데이터 무단 학습과 창작자 권리 침해 사례 확대
Nvidia가 GeForce Now 활용해 게임 플레이 영상 대량 수집, 개발사 허락 없이 AI 훈련 사용
OpenAI Sora의 게임 콘텐츠 학습 의혹, 다층 저작권 침해 가능성으로 법적 위험 부각
BBC·뉴욕타임스 등 주요 언론사의 법적 대응과 저작권 보호 요구 본격화
2025년 7월 SAG-AFTRA 협약 체결로 AI 디지털 복제 사용 시 사전 동의·7.5배 요율 의무화
지속가능한 데이터 윤리 체계와 한국 게임산업 대응 필요
클라우드플레어 Pay-Per-Crawl 모델 등 공정한 데이터 거래 시스템 도입 움직임 확산
EU AI Act 등 글로벌 AI 규제 강화로 훈련 데이터 저작권 보호 의무 확대립
한국 게임산업의 데이터 라이선스 계약 체계 마련 및 AI 사용 범위 명시 필요
업계 차원 AI 윤리 가이드라인 수립과 크롤러 차단 기술 선제 도입 시급
1. AI 기업의 스텔스 크롤링 실태와 웹 표준 위반 문제
Perplexity의 robots.txt 우회 및 신원 위장 크롤링 기법
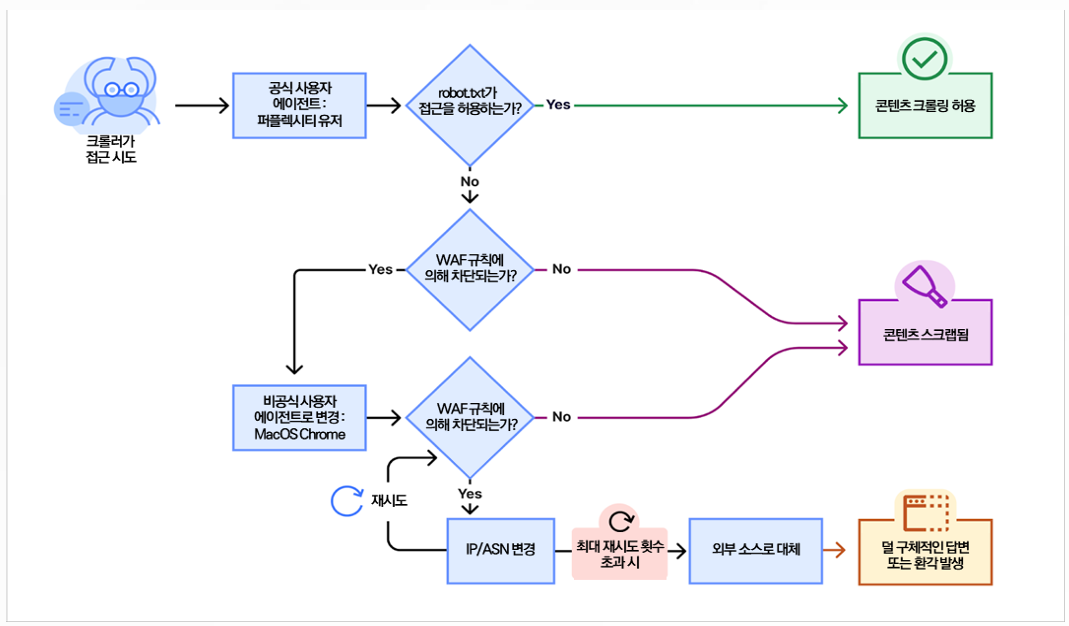
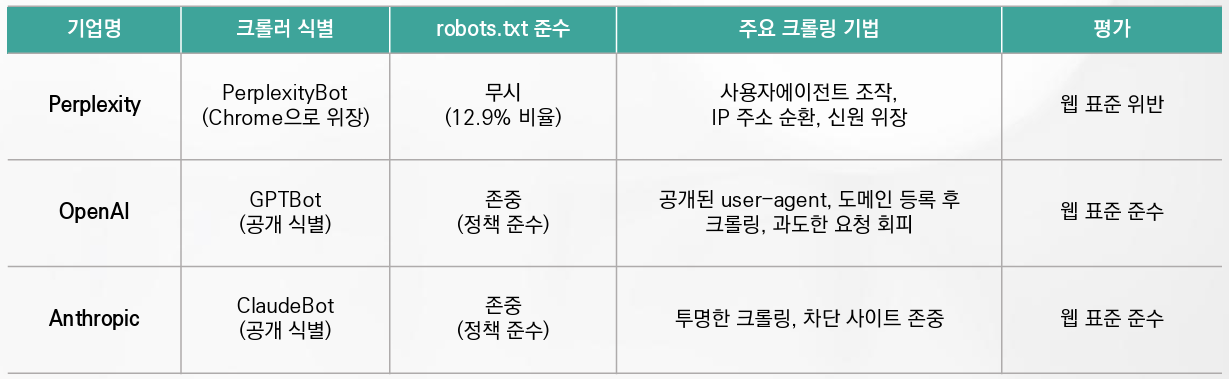
2025년 8월 클라우드플레어는 공식 블로그를 통해 AI 검색 스타트업 Perplexity의 크롤러5)가 웹사이트의 접근 제한을 우회하기 위해 사용자에이전트를 조작하고 IP 주소를 여러 네트워크로 순환시켜 신원을 숨기는 스텔스 크롤링 기법을 사용했다고 공개했다. 보고서에 따르면 Perplexity는 사이트가 자사 크롤러를 차단하면 공식 크롤러 이름인 “PerplexityBot” 대신 일반 Chrome 브라우저로 위장하고, IP 주소를 돌려가며 차단 목록을 피해 데이터를 수집했다. 하루 수백만 건의 요청을 수만 개 도메인에 보내는 동안 robots.txt6) 파일을 무시하거나 아예 요청하지 않는 사례도 다수 발견되었다. 이러한 행태는 웹 크롤링의 기본 원칙인 투명성, robots.txt 존중, 과도한 요청 회피 등을 정면으로 위반하는 것으로, 웹 생태계의 신뢰를 근본적으로 흔드는 문제로 지적받았다.
글로벌 미디어와 기술 분석 기관들도 이를 확인했다. The Verge는 Perplexity가 사이트 접근이 제한되면 사용자에이전트를 Google Chrome으로 조작하고 등록되지 않은 IP를 이용해 크롤링을 계속한다는 점을 지적했으며, 톨빗의 분석에 따르면 2025년 3월 AI 봇 가운데 robots.txt를 무시하는 비중은 12.9%로 전 분기의 3.3%에서 약 4배 가까이 급증한 것으로 나타났다. 같은 달에만 2,600만 건 이상의 AI 봇 스크래핑이 robots.txt를 무시한 것으로 집계되었다. 이처럼 무단 데이터 수집이 확산되면서 콘텐츠 제공자들은 자신들의 지식재산이 허락 없이 AI 모델 훈련에 사용되고 있다는 우려를 제기하고 있으며, 법적·윤리적 논란이 지속적으로 불거지고 있다.
RAG 봇 스크래핑 49% 증가와 robots.txt 무시 비율 확대
RAG 기반 AI 서비스7)는 외부 웹 데이터를 실시간으로 검색하고 추론해 답변을 생성하는 구조이므로, 최신 정보 확보를 위해 대량의 크롤링을 지속적으로 수행한다. 톨빗의 Q1 2025 보고서에 따르면 RAG 봇 스크래핑은 전 분기 대비 49% 증가했으며, AI 봇 트래픽은 일반 웹 트래픽 대비 87% 늘어난 것으로 나타났다. 특히 2025년 3월에는 AI 봇이 robots.txt를 무시한 요청이 급증하여, 무시 비율이 전 분기 3.3%에서 12.9%로 약 4배 가까이 증가했다. 이는 AI 기업들이 데이터 수집 경쟁에서 우위를 점하기 위해 웹 표준을 무시하고 공격적인 크롤링을 수행하고 있음을 의미한다. 결과적으로 콘텐츠 제공자들은 서버 부하 증가와 트래픽 비용 상승을 겪으면서도 AI 봇으로부터 유입되는 실질적인 방문자는 거의 없는 불공정한 상황에 놓이게 되었다.
더욱 심각한 문제는 AI 봇들이 콘텐츠를 대량으로 수집하면서도 사이트에 전달하는 참조 트래픽8)은 극히 적다는 점이다. Digiday가 정리한 데이터에 따르면 AI 기업들의 스크래핑 대 참조 트래픽 비율은 OpenAI가 179대 1, Perplexity가 369대 1, Anthropic이 8,692대 1에 달하는 것으로 나타났다. 이는 기존 검색엔진인 구글의 9.4대 1과 비교할 때 극심한 불균형을 보여준다. AI 봇들은 콘텐츠만 읽어가고 사용자 트래픽은 거의 돌려주지 않기 때문에, 언론사와 콘텐츠 제작자들은 광고 수익 감소와 IP 가치 하락이라는 이중고를 겪고 있다. 이러한 데이터 수집 방식은 웹 생태계의 공정한 교환 원칙을 무너뜨리며, 콘텐츠 생산자들의 지속가능한 창작 활동을 위협하고 있다.
2. 게임 데이터 무단 학습 사례와 창작자 권리 침해 실태
Nvidia의 게임 영상 스크래핑과 저작권 침해 논란
2024년 말 404 Media와 GameDeveloper.com이 확보한 Nvidia 내부 문건을 통해 충격적인 사실이 드러났다. Nvidia는 Omniverse 3D 세계 생성 기술 및 인간형 AI 모델 개발을 위해 YouTube와 Netflix는 물론 게임 플레이 영상을 대량으로 다운로드한 것으로 밝혀졌다. 내부 직원들의 증언에 따르면 Nvidia는 자사의 클라우드 게임 스트리밍 서비스인 GeForce Now를 활용해 고해상도 게임 영상을 직접 확보했으며, 크롤러를 통해 인터넷상의 게임 플레이 영상을 수집하라는 지시가 있었던 것으로 전해졌다. 문제는 이러한 데이터 수집 과정에서 게임 개발사나 콘텐츠 제작자의 허락을 전혀 구하지 않았다는 점이다. 게임 플레이 영상에는 게임 개발사의 저작권뿐 아니라 플레이어와 스트리머의 창작물이 포함되어 있어, 무단 사용 시 다층적인 저작권 침해 가능성이 제기되었다.
이 사건이 공론화되자 법적 대응도 즉각 이어졌다. 2024년 9월 유튜브 크리에이터들이 Nvidia를 상대로 집단 소송을 제기하며 자신들의 영상이 동의 없이 AI 훈련에 사용되었다고 주장했다. 게임업계에서는 이러한 무단 데이터 수집이 게임 개발사의 지식재산권을 침해할 뿐 아니라, 게임 콘텐츠 창작자들의 창작 동기를 훼손하고 시장 경쟁력을 약화시킬 수 있다는 우려가 확산되었다. 특히 인디 게임 개발사나 소규모 크리에이터의 경우 자신들의 게임 영상이나 아트워크가 AI 학습 데이터로 유출되면 이를 감지하거나 대응할 법적·기술적 수단이 부족해 더욱 취약한 상황에 놓여 있다. 이 사건은 AI 기업의 데이터 수집이 단순한 기술적 문제를 넘어 게임산업 생태계 전반의 신뢰와 지속가능성을 위협하는 문제임을 나타냈다.
<표> 게임 콘텐츠 저작권 구조와 AI 학습 시 법적 위험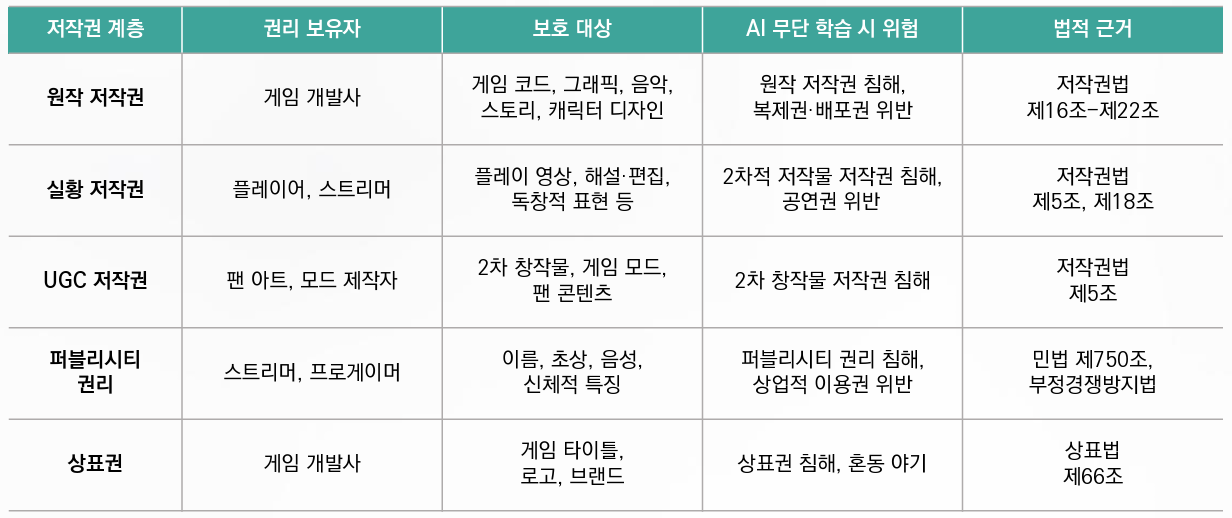
게임 플레이 영상 학습 의혹과 다층 저작권 침해 우려
2024년 12월 TechCrunch는 OpenAI의 영상 생성 모델 Sora가 게임 콘텐츠를 학습했을 가능성이 높다는 분석 기사를 발표했다. 보도에 따르면 Sora는 <마인크래프트>, <슈퍼마리오>, 1인칭 슈팅 게임, 격투 게임 등 특정 게임 장르를 연상시키는 영상을 생성하는 능력을 보여주었으며, 이는 해당 게임들의 플레이 영상과 Twitch 스트리머들의 실황 방송이 훈련 데이터에 포함되었을 가능성을 시사한다. IP 전문 변호사들은 게임 플레이 영상이 게임 개발사의 원작 저작권, 플레이어의 실황 저작권, UGC 제작자의 2차 창작물 권리 등 여러 층위의 저작권을 동시에 포함하고 있다고 지적했다. 따라서 이러한 영상을 허가 없이 AI 훈련에 사용하는 것은 단일 저작권 침해가 아닌 다층적 법적 위험을 안고 있으며, 각 권리자로부터 별도의 동의를 얻지 않는 한 소송에 직면할 가능성이 크다고 경고했다.
더욱 논란이 된 부분은 Sora가 생성한 영상 속에 실제 유명 스트리머의 신체적 특징까지 재현한 것으로 보이는 장면이 발견되었다는 점이다. TechCrunch는 특정 스트리머의 문신과 외모가 Sora가 생성한 영상에서 유사하게 나타나는 사례를 보도하며, 이는 퍼블리시티 권리 침해 가능성을 제기한다고 분석했다. 퍼블리시티 권리는 개인의 이름, 초상, 음성 등을 상업적으로 이용할 권리로, 본인의 동의 없이 AI가 이를 학습하고 재현하는 것은 명백한 권리 침해에 해당한다. 게임업계와 창작자 커뮤니티에서는 OpenAI가 “공개적으로 이용 가능한 데이터”라는 모호한 기준으로 게임 영상을 수집한 것으로 보이며, 이는 창작자의 권리를 무시한 일방적 데이터 수집이라는 비판이 제기되고 있다. 이 사건은 AI 기업이 데이터 수집 시 명확한 동의 절차와 보상 체계를 마련해야 한다는 요구를 더욱 강화시켰다.
<표> AI 기업의 게임 데이터 무단 학습 사례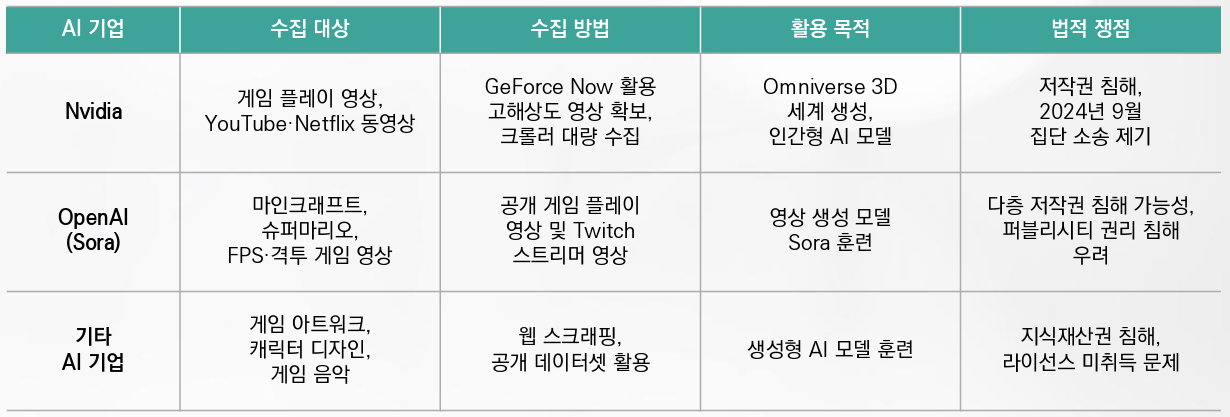
주요 언론사의 법적 대응과 저작권 보호 요구
AI 봇의 무단 크롤링과 콘텐츠 표절은 주요 언론사와 콘텐츠 제작자들의 강력한 법적 대응을 촉발했다. 영국 공영방송 BBC는 지난 6월 Perplexity에게 크롤링 즉각 중단, 훈련 데이터에서 BBC 콘텐츠 삭제, 그리고 금전적 보상을 요구하는 법적 경고장을 발송했다. 미국의 뉴욕타임스 역시 2024년 10월 Perplexity에 중단 및 금지 서한을 보내 자사 기사를 무단으로 요약하고 사용한 점을 지적하며 즉각적인 시정을 요구했다. Forbes와 Wired는 Perplexity가 운영하는 ‘퍼플렉시티 페이지’라는 도구에서 자사의 보도 내용과 이미지를 인용 표시 없이 그대로 복사했다고 폭로했으며, Perplexity CEO는 “미흡한 부분(rough edges)이 있었다”고 인정하며 문제의 심각성을 시인했다. 이러한 일련의 사건들은 AI 기업의 데이터 수집과 활용이 저작권을 침해할 가능성이 매우 크며, 콘텐츠 제공자들이 더 이상 이를 묵인하지 않겠다는 의지를 보여주고 있다.
게임산업 종사자들의 권리 보호도 본격화되고 있다. 2025년 7월 미국 배우 노조 SAG-AFTRA는 게임 제작사들과 인터랙티브 미디어 협약(Interactive Media Agreement)를 체결하며 AI 시대의 새로운 권리 보호 기준을 마련했다. 이 협약은 게임사가 배우나 성우의 디지털 복제본을 AI로 생성해 사용할 경우 반드시 사전 동의를 받고 사용 내역을 공개해야 한다고 명시했다. 특히 실시간 생성용 디지털 복제를 챗봇 등에 활용할 경우 기본 요율의 7.5배에 달하는 최소 보수를 지급해야 하며, 파업 중에는 배우가 동의를 철회할 권리를 보장한다. 또한 협약은 15.17%의 임금 인상과 애니메이션 및 모션캡처 배우에 대한 안전 규정도 포함하고 있어, 게임산업 종사자들의 종합적인 권익 향상을 도모했다. 이는 AI 기술이 창작자의 권리를 침해하지 않고 공존할 수 있는 제도적 기반을 마련한 사례로 평가받고 있다.
<표> 글로벌 콘텐츠 산업의 AI 데이터 수집 대응 사례 비교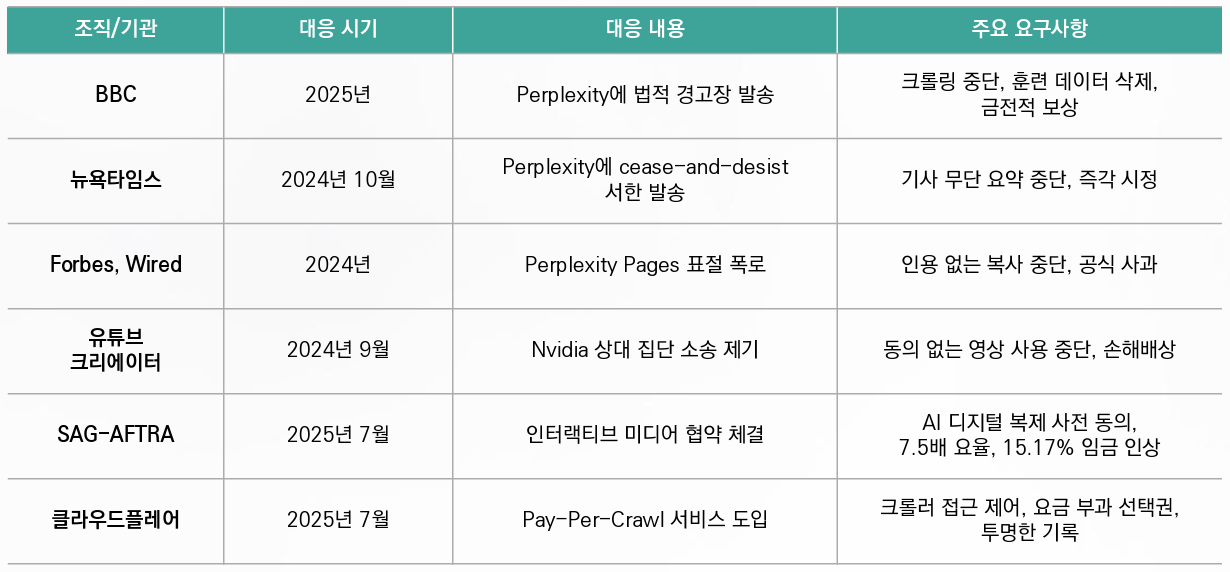
3. 한국 게임산업의 시사점과 대응 방안
지속가능한 데이터 윤리 체계 구축의 필요성
AI 기업의 무단 데이터 수집이 확산되면서 콘텐츠 생태계의 공정한 가치 교환을 위한 새로운 시스템이 필요해졌다. 클라우드플레어가 2025년 7월 도입한 ‘페이 퍼 크롤(Pay-Per-Crawl)’ 서비스는 이러한 문제를 해결하기 위한 시도이다. 페이 퍼 크롤 시스템은 웹사이트 소유자가 크롤러의 접근을 허용, 차단, 또는 요금 부과 중에서 선택할 수 있도록 하며, 요금을 선택할 경우 크롤러는 HTTP 402 “Payment Required” 응답을 받아 금액을 지불해야만 콘텐츠에 접근할 수 있다. 클라우드플레어는 이 서비스를 통해 AI 크롤링을 투명하게 기록하고 크롤러가 지불 의사를 표시하도록 해 데이터를 이용한 수익 공유를 가능하게 하는 것을 목표로 하고 있다. 실제로 하루 10억 건 이상의 402 응답이 발송되고 있으며, 극심한 크롤링 비율 불균형 문제를 해결하는 대안으로 주목받고 있는 것으로 알려졌다. 이러한 마이크로 지불 모델은 콘텐츠 제공자가 자신의 데이터에 대한 통제권을 회복하고 AI 기업과 공정한 거래 관계를 맺을 수 있는 기반을 제공한다.
글로벌 AI 규제 강화 추세도 데이터 윤리 체계 구축을 촉진하고 있다. EU AI Act를 비롯한 세계 각국의 규제 프레임워크는 AI 시스템이 안전하고 공정하며 투명하게 개발·배포되도록 요구하며, 특히 훈련 데이터의 저작권 및 개인정보 보호를 강조한다. 이러한 규제는 AI 활용 기업에 대해 데이터 수집과 라이선스 상태를 주기적으로 점검하고, 알고리즘 편향과 법적 위험을 평가하며, 사용자에게 AI 생성 콘텐츠를 명확히 고지하는 등 포괄적 거버넌스를 마련할 것을 권고한다. 한국 게임산업도 이러한 글로벌 기준에 선제적으로 대응해 저작권 데이터의 공정한 사용, 개인정보와 퍼블리시티 권리 보호, 알고리즘 편향 방지 등을 포함한 자체 윤리 가이드라인을 수립해야 한다. 이는 단기적으로는 규제 준수를 위한 부담으로 작용할 수 있으나, 장기적으로는 창작자와 AI 기술이 상생하는 건강한 생태계를 구축하는 데 필수적인 투자가 될 것이다.
한국 게임산업의 선제적 대응 전략
한국 게임산업은 AI 도구를 적극 활용하면서도 자사의 지식재산권을 보호하기 위한 구체적 전략을 마련해야 한다. 먼저 게임사는 AI 훈련 데이터에 포함될 가능성이 있는 모든 자산에 대한 라이선스 취득 여부를 철저히 확인하고, 계약서에 AI 사용 범위와 데이터 사용 허락 조항을 명시해야 한다. 특히 게임 플레이 영상, 캐릭터 디자인, 음악 등 다층적 저작권이 얽힌 자산의 경우 각 권리자로부터 별도의 동의를 받는 절차가 필요하다. 또한 AI가 생성한 게임 자산의 저작권 귀속과 퍼블리시티 권리 침해 여부를 명확히 하기 위해 새로운 계약 유형과 공정 사용 가이드라인을 개발해야 한다. SAG-AFTRA와 게임 제작사 간의 인터랙티브 미디어 협약은 AI 기술의 오남용을 방지하는 사례로, 디지털 복제 사용 시 사전 동의와 최소 보수, 동의 철회권 등을 명문화한 점에서 한국 게임업계에도 참고할 만한 기준을 제시하고 있다.
업계 차원의 집단 대응도 필요하다. 주요 개발사들은 공동으로 AI 윤리 가이드라인을 수립하고, 크롤러 차단 도구, 워터마크 삽입, 가짜 페이지 생성 등 기술적 보호 수단을 도입해 무단 학습을 어렵게 만들어야 한다. AI 혼란화 도구와 같은 솔루션을 활용하면 AI 봇이 게임 데이터를 수집하더라도 학습에 활용하기 어렵게 만들 수 있다. 또한 AI 개발자와 콘텐츠 제작자를 대상으로 저작권, 개인정보, 퍼블리시티 권리에 관한 교육을 실시하고, 윤리적 데이터 사용 지침을 보급해야 한다. 개발사에서는 공식 모드 개발 도구를 제공해 팬이 생성한 콘텐츠를 관리하면서 합법적 활용을 도울 수 있으며, 학계와 비영리 연구 기관은 공정 사용 범위 내에서 공개 데이터셋을 구축해 연구용 AI가 합법적으로 발전할 수 있도록 지원해야 한다. 이처럼 다층적이고 협력적인 대응을 통해 한국 게임산업은 AI 시대의 도전을 기회로 전환하고, 창작자의 권리를 보호하면서도 기술 혁신을 주도하는 위치를 확보할 수 있을 것으로 전망된다.
참고문헌
- TollBit, "State of the Bots Q1 2025", https://tollbit.com/bots/25q1/
- Cloudflare Blog, "Perplexity is using stealth, undeclared crawlers to evade website no-crawl directives", 2025년 8월, https://blog.cloudflare.com/perplexity-is-using-stealth-undeclared-crawlers-to-evade-website-no-crawl-directives/
- The Verge, "Cloudflare says Perplexity's AI bots are 'stealth crawling' blocked sites", https://www.theverge.com/news/718319/perplexity-stealth-crawling-cloudflare-ai-bots-report
- Digiday, "Here are the biggest misconceptions about AI content scraping", https://digiday.com/media/here-are-the-biggest-misconceptions-about-ai-content-scraping/
- TechCrunch, "It sure looks like OpenAI trained Sora on game content — and legal experts say that could be a problem", 2024년 12월, https://techcrunch.com/2024/12/11/it-sure-looks-like-openai-trained-sora-on-game-content-and-legal-experts-say-that-could-be-a-problem/
- Cybernews, "BBC threatens to sue Perplexity over content scraping", https://cybernews.com/ai-news/bbc-legal-action-perplexity-content-scraping-/
- Reuters, "NYT sends AI startup Perplexity 'cease and desist' notice over content use", 2024년 10월, https://www.reuters.com/technology/artificial-intelligence/nyt-sends-ai-startup-perplexity-cease-desist-notice-over-content-use-wsj-reports-2024-10-15/
- Forbes, "The Prompt: Perplexity's Plagiarism Problem", 2024년 6월, https://www.forbes.com/sites/rashishrivastava/2024/06/11/the-prompt-perplexitys-plagiarism-problem/
- Wired, "Perplexity Plagiarized Our Story About How Perplexity Is a Bullshit Machine", https://www.wired.com/story/perplexity-plagiarized-our-story-about-how-perplexity-is-a-bullshit-machine/
- GameDeveloper.com, "Report: NVIDIA used scraped video game footage to train AI products", 2024년, https://www.gamedeveloper.com/business/report-nvidia-used-scraped-video-game-footage-to-train-ai-products
- 404 Media, "Nvidia Sued for Scraping YouTube After 404 Media Investigation", 2024년 9월, https://www.404media.co/nvidia-sued-for-scraping-youtube-after-404-media-investigation/
- Odin Law and Media, "The Game Developer's Guide to AI Governance", https://odinlaw.com/blog-ai-governance-in-game-development/
- Reuters, "Industry video game actors pass agreement with studios for AI security", 2025년 7월, https://www.reuters.com/business/media-telecom/industry-video-game-actors-pass-agreement-with-studios-ai-security-2025-07-10/
- The Wrap, "SAG-AFTRA Reveals First Details on Video Game Deal", https://www.thewrap.com/sag-aftra-video-game-deal-details/
- eWeek, "Cloudflare Rolls Out Pay-per-Crawl System for AI Bots to All Customers", 2025년 7월, https://www.eweek.com/news/cloudflare-expands-ai-crawler-control/
- DLA Piper, "Games Saw it Coming: Decoding Generative AI Controversy Through the Lens of Play", 2025년 7월, https://www.dlapiper.com/en-hk/insights/publications/2025/07/decoding-generative-ai-controversy-through-the-lens-of-play